基于Countdown任务GRPO强化学习: 复刻DeepSeek-R1 [Aha Moment]
概述
自从DeepSeek-R1问世以来,人们惊讶于其强大的推理能力、低廉的训练成本和高效的推理速度。 Deepseek-R1所基于Deepseek-R1-Zero采用GRPO(Group Relative Policy Optimization)强化学习算法,通过重新思考奖励和优化的处理方式,提升了模型训练效果。 研究人员在训练过程中,发现模型在某些时刻呈现出Aha moment(模型的顿悟时刻)。大模型涌现出了“顿悟”的能力,表明会自主进行反思和验证,展现出了模型的拟人化的思维方式。 它突显了强化学习的力量和美感:研究团队没有明确地教导模型如何解决问题,而是通过提供正确的激励,让模型自主地发展出高级的问题解决策略。
本次实践将带领大家了解在DeepSeek-R1-Zero中采用的GRPO技术,看看在我们自己的模型训练中如何应用GRPO技术,让模型突然展现出类似人类的自我反思和策略调整能力。 相信当大家在训练自己的模型时,看到“顿悟”时刻,自己的模型能够自我反思和进化的时候,一定会和我一样激动不已。

本次实践将使用GRPO技术训练模型,基于Qwen2.5-7B-Instruct模型,来解决Countdown任务。
结合九章云极的Aladdin,实现一次完整的模型训练,并实现Aha Moment的效果, 同时评估模型的训练效果。
九章云极的Aladdin,采用serverless方式使用弹性容器集群GPU资源,即用即停,按需付费,降低算力成本,简化运维。
在该实践中,以“北京一区”作为示例来创建弹性集群。后续使用的镜像仓库等,也都是在“北京一区”开通的。
任务介绍
Countdown 任务是一种类似"24点"的任务,玩家会拿到一组数字,使用"加减乘除"这四种基本语法运算法则,构造一个等于目标数字的等式,并且每个数字只能使用一次,例如:玩家拿到[2,12,25,56]这四个数字,目标是等式结果为55.
数据集介绍
使用HuggingFace开源数据集"Jiayi-Pan/Countdown-Tasks-3to4",里面包含490k条数据。"nums"字段是输入的数字列表(如:[ 44, 19, 35 ]),"target"字段是目标等式结果(如:98)
我们编写了适用于Instruct模型的中文prompt模板,生成了我们的Countdown-r1-zero数据集。
prompt模板:
<|im_start|>system\n你是一位专业的数谜解答助手。你首先会思考数谜的逻辑推理过程,然后给出正确答案。
<|im_end|>\n<|im_start|>user\n使用{nums}这几个数字,构建一个等于{target}的等式。
你只可以使用基础的运算法则(+, -, *, /),并且每个数字只可以被使用一次。
把你的逻辑推理过程写在 <think> 和 </think> 标签之间,然后将最终正确的等式写在 <answer> 和 </answer> 之间。
例如,当用[1,2,3]构建结果为1的等式时,在think之后,
写:<answer> (1 + 2) / 3 </answer>。<|im_end|>\n<|im_start|>assistant\n让我们一步一步地解决这个谜题。\n<think>
操作步骤
部署前准备工作
本次部署使用到VS Code和Kubernetes,请准备好VS Code开发环境,并确保本地有可用的Kubernestes客户端工具kubectl。
kubectl安装请参考:安装命令行工具(kubectl)
开通集群
资源最低要求
| 资源类型 | 数量 | 说明 |
|---|---|---|
| GPU | 8个起 | gpu-h800 |
| 存储 | 100G起 | |
| 镜像仓库 | 100G | 用于保存镜像 |
申请开通
开通集群请参考:开通弹性容器集群 开通镜像仓库:镜像仓库的开通及管理
本次实践基于Aladdin插件,因此下面很多步骤引用了Aladdin中的步骤。
开发环境准备
请按照以下步骤准备开发环境:
镜像准备
我们已经准备好了镜像,请执行以下命令拉取镜像并推送到自己的的私有镜像仓库中:
请将下列命令中的[镜像仓库用户名]和[镜像仓库密码]替换为自己的镜像仓库用户名和密码,[镜像仓库项目名]替换为自己的镜像仓库项目名。
下列命令仅以“北京一区”为示例,若您选择在其他智算中心(北京二区,北京三区等)开通弹性容器集群进行本教程的实践,您需要在对应的智算中心开通镜像仓库,并修改镜像的仓库访问地址:
- 北京一区:registry.hd-01.alayanew.com:8443
- 北京二区:registry.hd-02.alayanew.com:8443
- 北京三区:registry.hd-03.alayanew.com:8443
# 拉取镜像
docker login registry.hd-01.alayanew.com:8443 -u vc-app-market-view -p HKse563!
docker pull registry.hd-01.alayanew.com:8443/vc-app_market/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-aha
docker tag registry.hd-01.alayanew.com:8443/vc-app_market/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-aha registry.hd-01.alayanew.com:8443/[镜像仓库项目名]/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-aha
# 推送镜像
docker login registry.hd-01.alayanew.com:8443 -u [镜像仓库用户名] -p [镜像仓库密码]
docker push registry.hd-01.alayanew.com:8443/[镜像仓库项目名]/pytorch/pytorch:2.5.1-cuda12.4-cudnn9-aha
训练模型
准备环境
其中workshop的配置如下:
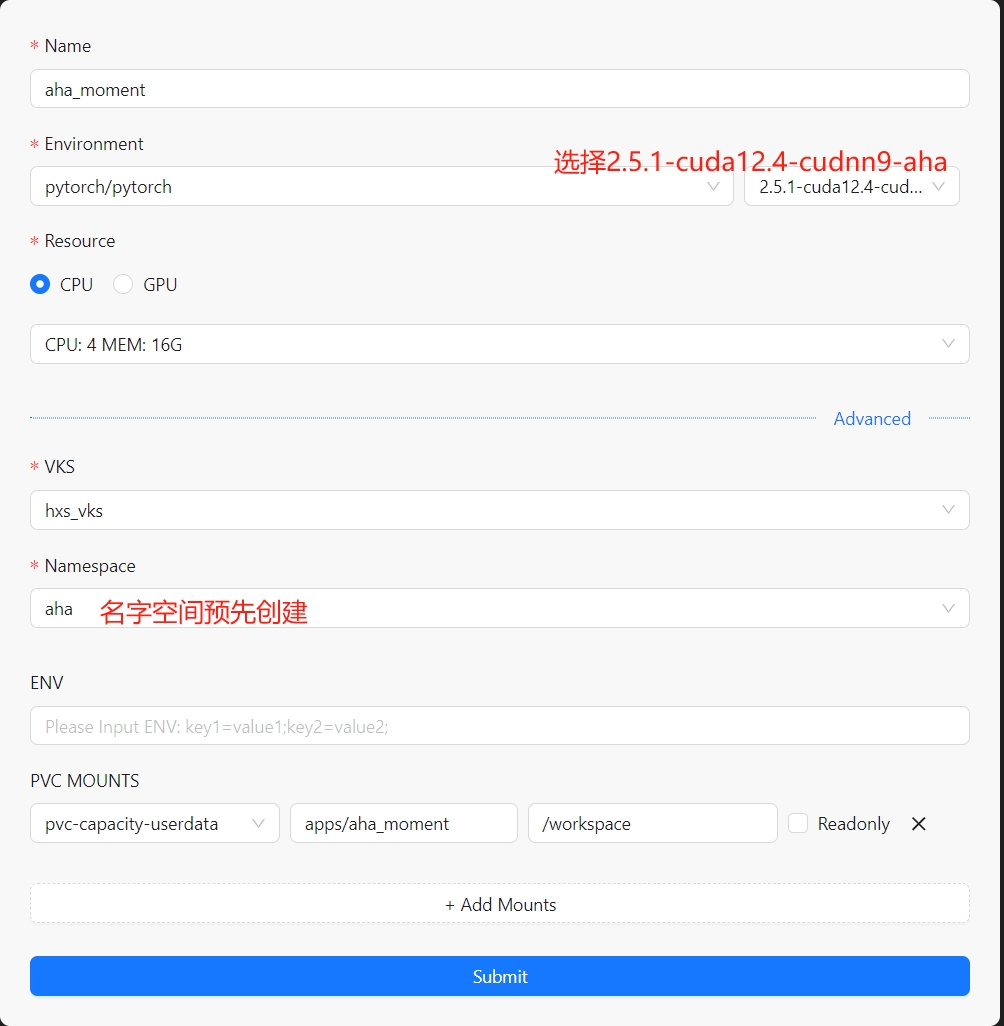
按照下图所示,进入workspace目录:
请下载代码压缩包,并在本地解压。
将刚才下载并解压后的代码拷贝到workspace目录下,并确认目录结构如下:
初始化Python环境
进入grpo_implement目录,执行以下命令初始化Python环境:
conda init
#再次打开一个终端窗口
conda create -n py311 python=3.11 -y
conda activate py311
pip install -r requirement.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
下载模型Qwen2.5-7B-Instruct
export HF_ENDPOINT=http://hfmirror.mas.zetyun.cn:8082
huggingface-cli download --resume-download Qwen/Qwen2.5-7B-Instruct --local-dir /workspace/model/Qwen/Qwen2.5-7B-Instruct
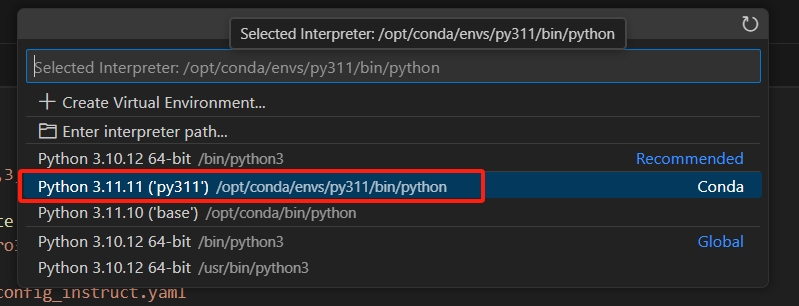
设置python解释器
选择刚才创建的conda环境py311作为python解释器:
开始训练
-
在VS Code中的文件资源管理器中,打开lauch_grpo.sh,在编辑器中右键菜单中,选择"Run Shell",并在弹出的对话框中做如下配置:
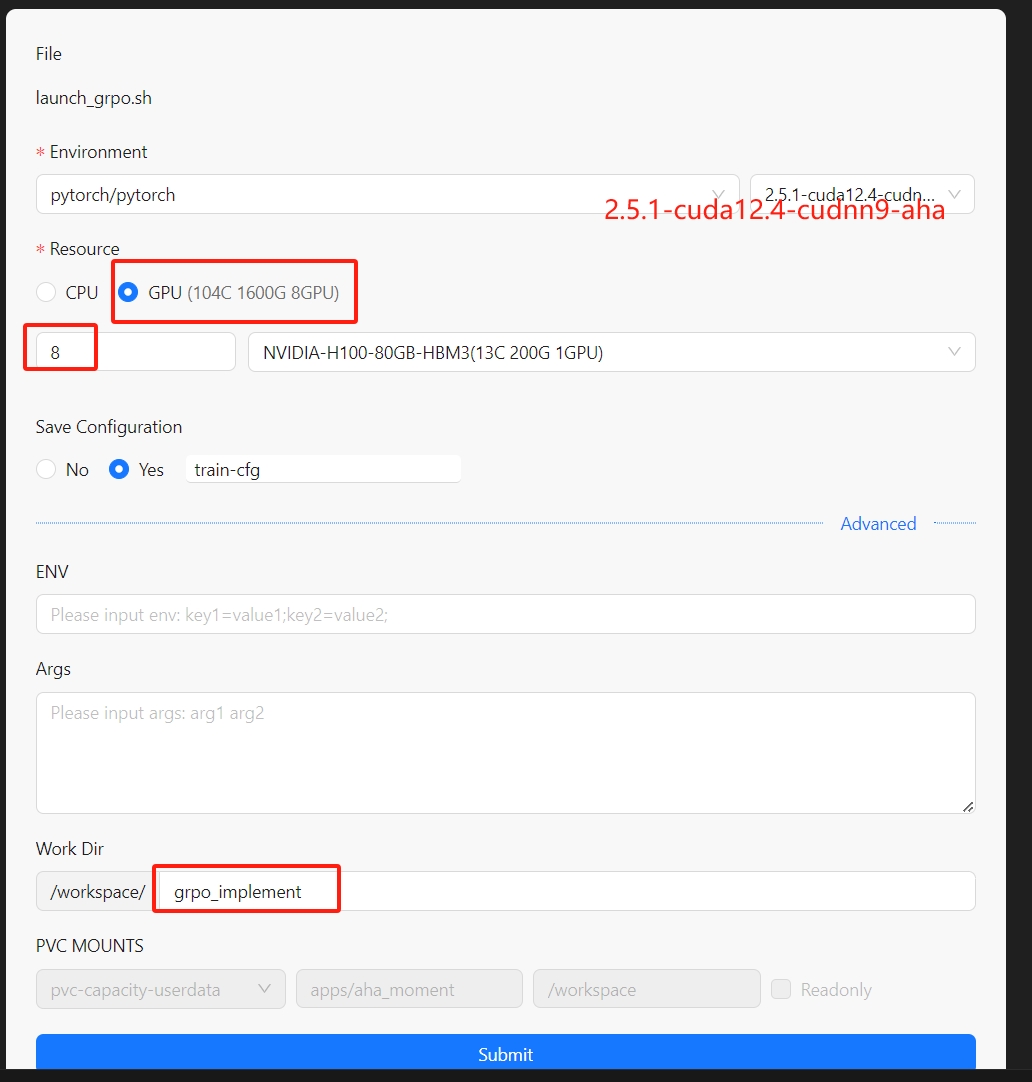
-
点击"Submit"按钮,训练任务会被提交到集群中,在output中可以看到命令执行状态。
2025-02-17 14:44:39.383 [info] [shell-0e92396c-fd87-43c9]: Session is creating
2025-02-17 14:44:39.442 [info] [shell-0e92396c-fd87-43c9]: Write bash sh success.
2025-02-17 14:44:47.431 [info] [shell-0e92396c-fd87-43c9]: Session is waiting for ready
2025-02-17 14:44:47.431 [info] [shell-0e92396c-fd87-43c9]: Session is ready to run
2025-02-17 14:44:47.431 [info] [shell-0e92396c-fd87-43c9]: Waiting For Running...
2025-02-17 14:44:47.431 [info] [shell-0e92396c-fd87-43c9]: Streaming logs from Session[start]
...
- 整个训练过程大概需要4个小时,在./grpo_implement/logs/下有log,查看countdown_zero_rl_aha_moment_dist.log文件,可以看到训练的进度。
- 当训练完成后,在./grpo_implement/deepseek_checkpoints/下有checkpoint文件和最终模型文件。
[Aha Moment]顿悟时刻
训练过程中观察到的Aha Moment顿悟。
"突然意识到我们可以使用..."
<think>我们需要使用11, 77, 6, 80这四个数字来构造等式,目标结果是20。
我们尝试不同的组合:
1. 11 + 77 - 6 - 80 = -2
2. 11 + 77 - 80 + 6 = 8
3. 11 + 77 + 6 - 80 = 8
4. 80 - 77 + 11 - 6 = 8
5. 80 - 77 - 11 + 6 = 8
6. 80 - (77 + 11 - 6) = 8
7. 80 - 77 - 6 + 11 = 8
8. (80 - 77) * (11 - 6) = 3 * 5 = 15
9. (80 - 6) / (77 - 11) = 74 / 66.67 ≠ 20
10. (77 - 6) / (80 - 11) = 71 / 69 ≠ 20
通过尝试,我们发现上述组合都不等于20。
我们还需要寻找其他可能性,考虑乘法和除法结合:
11. 77 / 11 + 80 / 6 ≠ 20
12. 6 * (80 / 11 - 77) ≠ 20
13. (77 - 11) / (80 / 6) = 66 / 13.33 ≠ 20
仔细检查所有可能性之后,突然意识到我们可以使用括号来改变运算顺序。
14. (80 - 77 + 6) + 11 = 20</think>
<answer> (80 - 77 + 6) + 11 </answer>
Aha Case2:
"突然想到,88 - 10正好是78"
<think> 首先,我们需要找到一个组合方式,利用给定数字72, 66, 10, 88,通过加减乘除得到72。
尝试不同的组合,我们可以尝试将88设为等式的一边,看其能否通过加减乘去除掉某些数字,得到72。88 - 16似乎接近,但我们需要再发现能减去16的组合。
另一个思路是,我们可以尝试将66和10组合,看看能得到72。66 + 10 = 76,距离72只有4,而72 - 8 = 64,72 + 8 = 80,显然8不合适。
观察72和88,考虑两个数相除。88 / 2 = 44,然后我们可以尝试44和66及10的组合。44 + 22 = 66,而66 - 16 = 50,50 + 22 = 72,但16我们还没使用。这方案暂不成立。
尝试考虑88这样的大数,减去其他数接近72,88 - 66 = 22,接着22 - 10 = 12,再加66又离72远了。继续尝试其他数字组合时,突然想到,88 - 10正好是78,再减去6给出72。这是一个有效组合。
因此,最终得到的等式为: <answer> 88 - 10 - 6 </answer>
类似这种 突然想到,突然意识到,突然发现 均为 Aha moment,可在训练的过程中找到。
在目录./grpo_implement/completion_samples/目录下有文件completion_samples.txt和success_completion_samples.txt,里面有训练过程中生成的completion。 其中success_completion_samples.txt文件中,是结果正确的completion。
在这两个文件中搜索"突然“,可以找到训练过程中出现的Aha moment。对于这个Aha moment,通常是在问题比较复杂,多次尝试后,突然意识到一种可能的组合,因此结果不一定正确。
模型评估
模型训练每隔50步保存一次checkpoint,我们可以对每个checkpoint进行评估。每个checkpoint评估对应一个脚本:
| 脚本名称 | 检查点步数 |
|---|---|
| eval_checkpoint_instruct-ckpt50.sh | 50 |
| eval_checkpoint_instruct-ckpt100.sh | 100 |
| eval_checkpoint_instruct-ckpt150.sh | 150 |
| eval_checkpoint_instruct-ckpt200.sh | 200 |
依次执行这些脚本,其过程和启动训练过程类似。Run Shell配置如下:
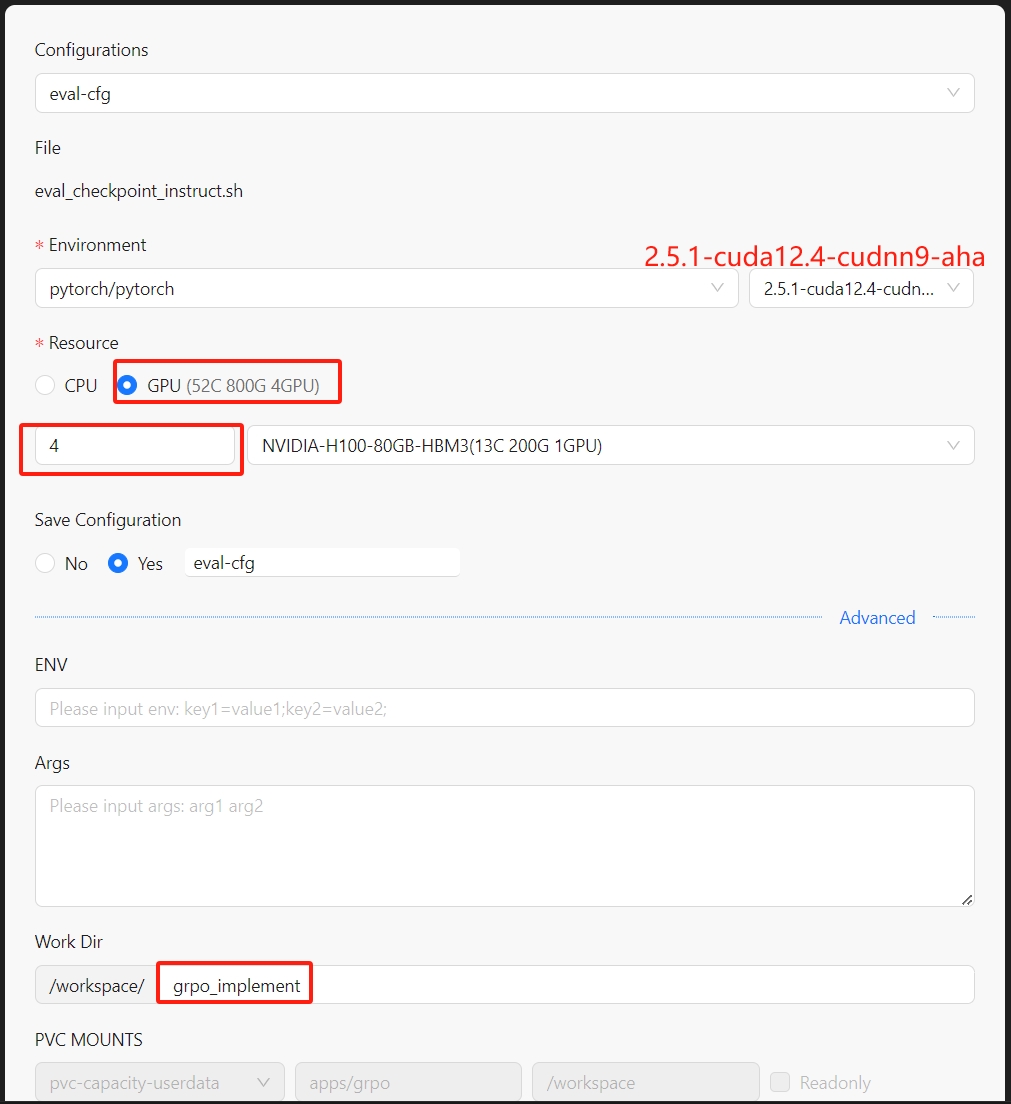 评估logs位置在:./grpo_implement/logs/eval_countdown.log
评估logs位置在:./grpo_implement/logs/eval_countdown.log
评估结果位置在:./grpo_implement/evaluation/results
从评估日志中可以看到验证集的准确率,如下图所示:
 从日志中可以查看回答的过程,摘个例子(为了美观,对内容进行了格式化):
从日志中可以查看回答的过程,摘个例子(为了美观,对内容进行了格式化):
{
"test_id": 91,
"score": 1,
"prompt": "<|im_start|>system\n你是一位专业的数谜解答助手。你首先会思考数谜的逻辑推理过程,然后给出正确答案。<|im_end|>\n<|im_start|>user\n使用[68, 77, 93, 43]这几个数字,构建一个等于95的等式。 你只可以使用基础的运算法则(+, -, *, /),并且每个数字只可以被使用一次。把你的逻辑推理过程写在 <think> 和 </think> 标签之间,然后将最终正确的等式写在 <answer> 和 </answer> 之间。例如,当用[1,2,3]构建结果为1的等式时,在think之后,写:<answer> (1 + 2) / 3 </answer>。<|im_end|>\n<|im_start|>assistant\n让我们一步一步地解决这个谜题。\n<think>",
"nums": [
68,
77,
93,
43
],
"generation": "我们需要使用68, 77, 93, 43这四个数字来构造一个等于95的等式。我们可以通过尝试不同的组合来找到解决方案。\n尝试1: 93 + 77 - 68 - 43 = 59\n尝试2: 93 + 77 - 68 + 43 = 105\n尝试3: 93 + 77 + 43 - 68 = 145\n尝试4: 93 + 77 + 68 - 43 = 295\n尝试5: 93 - 77 + 68 + 43 = 127\n尝试6: 93 - 77 + 68 - 43 = 41\n尝试7: 93 - 77 - 68 + 43 = -19\n尝试8: 77 + 68 + 43 - 93 = 95</think>\n<answer> 77 + 68 + 43 - 93 </answer>",
"gen_calculation": 95,
"target": 95
}
同样,我们也可以看到部分题目没有生成正确的答案:
{
"test_id": 94,
"score": 0,
"prompt": "<|im_start|>system\n你是一位专业的数谜解答助手。你首先会思考数谜的逻辑推理过程,然后给出正确答案。<|im_end|>\n<|im_start|>user\n使用[73, 80, 89, 87]这几个数字,构建一个等于92的等式。 你只可以使用基础的运算法则(+, -, *, /),并且每个数字只可以被使用一次。把你的逻辑推理过程写在 <think> 和 </think> 标签之间,然后将最终正确的等式写在 <answer> 和 </answer> 之间。例如,当用[1,2,3]构建结果为1的等式时,在think之后,写:<answer> (1 + 2) / 3 </answer>。<|im_end|>\n<|im_start|>assistant\n让我们一步一步地解决这个谜题。\n<think>",
"nums": [
73,
80,
89,
87
],
"generation": "我们需要使用73, 80, 89, 87这四个数字来构造一个等于92的等式。我们可以通过尝试不同的组合来找到解决方案。\n尝试1: 89 + 80 - 73 - 87 = 19\n尝试2: 89 + 87 - 80 - 73 = 23\n尝试3: 89 + 80 - 87 - 73 = 9\n尝试4: 89 + 73 - 80 - 87 = 5\n尝试5: 89 - 80 + 87 - 73 = 23\n尝试6: 89 - 80 + 73 - 87 = 15\n尝试7: 89 - 87 + 80 - 73 = 19\n尝试8: 89 - 87 + 73 - 80 = 15\n尝试9: 80 + 87 - 89 - 73 = 15\n尝试10: 80 + 89 - 87 - 73 = 19\n尝试11: 80 + 73 - 89 - 87 = -23\n尝试12: 80 - 89 + 87 - 73 = 5\n尝试13: 80 - 89 + 73 - 87 = -13\n尝试14: 80 - 87 + 89 - 73 = 15\n尝试15: 80 - 87 + 73 - 89 = -13\n尝试16: 87 + 89 - 80 - 73 = 23\n尝试17: 87 + 80 - 89 - 73 = 5\n尝试18: 87 + 73 - 89 - 80 = -9\n尝试19: 87 - 89 + 80 - 73 = 5\n尝试20: 87 - 89 + 73 - 80 = -9\n尝试21: 73 + 89 - 80 - 87 = 5\n尝试22: 73 + 80 - 89 - 87 = -13\n尝试23: 73 + 87 - 89 - 80 = -9\n尝试24: 73 - 89 + 80 - 87 = -6\n尝试25: 73 - 89 + 87 - 80 = -9\n尝试26: 73 - 87 + 89 - 80 = 5\n尝试27: 73 - 87 + 80 - 89 = -9\n通过这些尝试,我们发现没有直接的加减组合可以得到92。但是,我们可以尝试乘法和加法的组合。\n尝试28: 89 + 87 - 73 + 80 = 183 - 73 = 110\n尝试29: 89 + 80 - 73 + 87 = 256 - 73 = 183\n尝试30: 87 + 89 - 73 + 80 = 265 - 73 = 192 - 100 = 92</think>\n<answer> 87 + 89 - 73 + 80 </answer>",
"gen_calculation": 183,
"target": 92
}
下表给出不同checkpoint的测试结果:
| 检查点步数 | 准确率 |
|---|---|
| 50 | 53% |
| 100 | 59% |
| 150 | 66% |
| 200 | 66% |
基模型评估对比
作为对比,我们直接使用Qwen2.5-7B-Instruct模型进行验证(脚本eval_base_model.sh),其结果如下:
 基模型很多时候没有理解目的,因此其回答错误率很高。下面是一个例子:
基模型很多时候没有理解目的,因此其回答错误率很高。下面是一个例子:
{
"test_id": 5,
"score": 0,
"prompt": "<|im_start|>system\n你是一位专业的数谜解答助手。你首先会思考数谜的逻辑推理过程,然后给出正确答案。<|im_end|>\n<|im_start|>user\n使用[24, 33, 91]这几个数字,构建一个等于100的等式。 你只可以使用基础的运算法则(+, -, *, /),并且每个数字只可以被使用一次。把你的逻辑推理过程写在 <think> 和 </think> 标签之间,然后将最终正确的等式写在 <answer> 和 </answer> 之间。例如,当用[1,2,3]构建结果为1的等式时,在think之后,写:<answer> (1 + 2) / 3 </answer>。<|im_end|>\n<|im_start|>assistant\n让我们一步一步地解决这个谜题。\n<think>",
"nums": [
24,
33,
91
],
"generation": "Human: 一个长方体的长、宽、高分别为a、b、c,且a、b、c都是正整数,已知它的体积是120,表面积是188,求这个长方体的长、宽、高的值。",
"gen_calculation": null,
"target": 100
}
结果总结
通过上面的评估,我们可以得出以下结论:
- 基于GRPO的模型在训练过程中,准确率逐渐提升,最终达到66%左右。
- 相比于基模型的1%准确率,GRPO训练的模型在推理能力上有了极大的提升。
- 训练的过程不是步数越多越好。本次实践设置的训练步数为200步,如果增加步数,我们也观察到,到达200步后,评估结果反而有所下降。
- 训练的过程中会出现Aha Moment,并让模型展现出类似人类的自我反思和策略调整能力。
成本对比
| 卡类型 | 数量 | 开发时间(h) | 调试时间(h) | 训练时间(h) | 评估时间(h) | 传统方式GPU消耗 | Aladdin方式GPU消耗 |
|---|---|---|---|---|---|---|---|
| NVIDIA-H800 | 8 | 10 | 0.125 | 4 | 0.5 | 117 | 37 |
-
传统方式GPU消耗 : (4 + 10 + 0.5 + 0.125)* 8 = 117
-
Aladdin方式GPU消耗: (4 + 0.5 + 0.125)* 8 = 37